What is LLM?A Large Language Model (LLM) is an artificial intelligence program trained on immense datasets of text and code, enabling it to understand, generate, and process human language with remarkable fluency. These sophisticated algorithms learn patterns, grammar, and context from the vast data, allowing them to perform a wide range of natural language processing tasks such as answering questions, translating languages, summarizing documents, writing various creative content formats, and engaging in coherent conversation by predicting the most probable sequence of words. What is Open-Source LLM?Open Source Large Language Models (LLMs) represent a significant shift in the landscape of artificial intelligence, democratizing access and fostering innovation in a field previously dominated by proprietary solutions. These models typically provide public access to their foundational components, enabling transparency, customizability, and community-driven development. 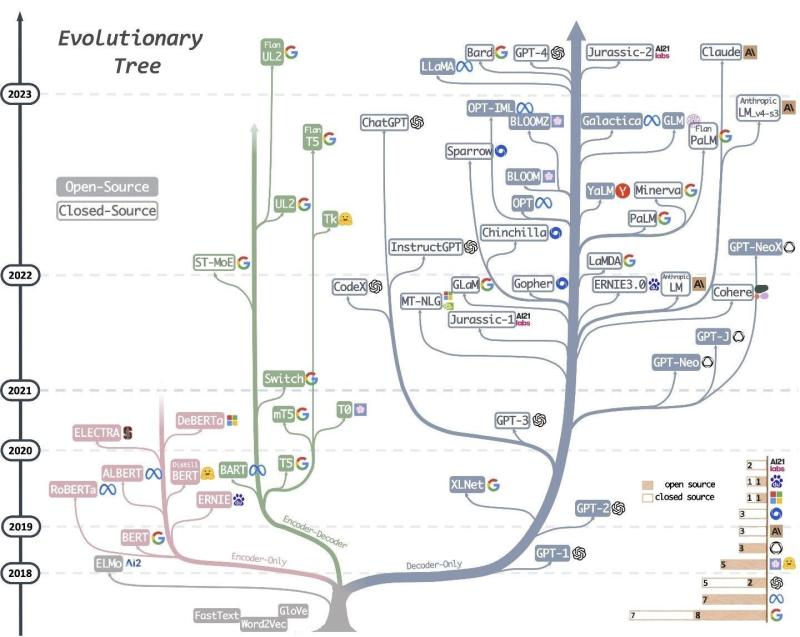
Definition & Scope for Open Source LLMAn LLM is considered "open source" when its model weights, architecture, and often the training code, datasets, or at least detailed methodologies, are publicly available. This allows anyone to inspect, modify, and deploy the model. - Variations in "Openness": It's important to note that the term "open source" can have nuances. Some models offer truly permissive licenses (e.g., Apache 2.0, MIT) allowing unrestricted commercial use, while others (like early Llama versions) might have specific restrictions based on usage scale or commercial intent. The trend is moving towards more permissive licensing for competitive reasons.
Core Components & Characteristics:- Model Architecture: Most open-source LLMs are based on the Transformer architecture, primarily decoder-only models, designed for generative tasks. Examples include standard Transformers, Mixture-of-Experts (MoE) architectures, and specialized variants.
- Training Data: These models are pre-trained on vast and diverse datasets, typically comprising trillions of tokens from web crawls, books, code repositories, academic papers, and conversational data. The quality, diversity, and filtering of this data are critical for model performance and mitigating biases.
- Training Process: The process usually involves:
- Pre-training: Unsupervised learning on a massive corpus to predict the next token, building a foundational understanding of language, facts, and reasoning.
- Fine-tuning: Supervised fine-tuning (SFT) on specific, high-quality instruction datasets to improve instruction following.
- Reinforcement Learning from Human Feedback (RLHF) / Reinforcement Learning from AI Feedback (RLAIF): Further alignment with human preferences, safety guidelines, and helpfulness, reducing undesirable outputs.
Inference & DeploymentOpen-source models can be used on different systems, from personal computers with enough power to cloud-based GPU clusters, providing more options than just using API-only proprietary models. Evaluation & BenchmarkingPerformance is rigorously evaluated against standardized benchmarks (e.g., MMLU, HELM, GSM8K, HumanEval) as well as custom enterprise-specific metrics for specific use cases. Benefits- Transparency & Auditability: Allows users to inspect the model's inner workings, understand potential biases, and verify its safety and reliability.
- Customization: Enables fine-tuning for specific domains, tasks, languages, or brand voices, leading to highly specialized and performant applications.
- Innovation: Fosters rapid experimentation and collaboration within the global AI community, leading to faster development of new techniques, tools, and applications.
- Cost-Effectiveness: Eliminates recurring API usage fees, significantly reducing operational costs for high-volume or extensive deployments.
Challenges- Computational Resources: Training and even running inference for larger models can still be computationally intensive, requiring substantial hardware resources (GPUs).
- Safety & Bias Mitigation: While fine-tuning helps, ensuring safety and mitigating biases can be an ongoing challenge, requiring careful data curation and alignment techniques.
- Maintenance & Support: The level of ongoing support can vary greatly compared to commercial proprietary models, relying heavily on community contributions.
- Performance Gap: While closing rapidly, some proprietary models might still hold an edge in specific niche capabilities or general instruction following, particularly the very largest models.
Hottest LLM Models at This Point (as of Q2 2024)The landscape of LLMs is incredibly dynamic, with new models and updates emerging constantly. "Hottest" can refer to performance, adoption, innovation, or community buzz. However, some models consistently stand out: Meta Llama 3: Recently released, Llama 3 (8B and 70B parameters, with larger versions planned) has quickly become a leading contender in the open-source space. It demonstrates state-of-the-art performance, often matching or exceeding proprietary models of similar sizes on various benchmarks. Its strong instruction-following capabilities and relatively permissive license have driven rapid adoption. 
- Mistral AI Models (Mistral 7B, Mixtral 8x7B, Mistral Large): Mistral AI has garnered immense attention for its highly efficient and performant models.
Google Gemma: Derived from Google's proprietary Gemini models, Gemma (2B and 7B parameters) offers lightweight, high-quality models suitable for research and smaller-scale deployments. It's designed to be developer-friendly and integrates well within the Google ecosystem. 
Databricks DBRX: An impressive Mixture-of-Experts (MoE) model from Databricks, DBRX boasts strong performance across various benchmarks, particularly in coding, math, and logic. Its architecture is optimized for efficiency and quality. 
- Specialized and Fine-tuned Models: Beyond foundational models, the "hotness" extends to a myriad of fine-tuned models built upon these foundations for specific tasks, such as:
- Code Generation: Models derived from Llama (e.g., CodeLlama, Phind-CodeLlama) or Mistral, specialized in generating and understanding code.
- Medical/Science: Models fine-tuned on biomedical literature for specific research or clinical applications.
- Multimodal Models: Models like LLaVA, which combine vision encoders with LLMs to understand and generate text based on image inputs, are rapidly gaining traction for their versatile capabilities.
Why Open Source LLMs Are Hot?The surge in popularity and development of open-source LLMs is driven by a confluence of technological advancements, strategic shifts, and growing community demand: - Accelerated Innovation and Community Collaboration:
- Faster Iteration: Open access allows a global community of researchers and developers to experiment, contribute improvements, identify bugs, and build new applications at an unprecedented pace.
- Diversification of Use Cases: This collaborative environment leads to a wider range of specialized models and applications that might not be prioritized by a single proprietary vendor.
- Customization and Specialization:
- Domain-Specific Adaptation: Businesses and researchers can fine-tune open-source models with their proprietary data, creating highly specialized LLMs that excel in niche domains (e.g., legal, medical, finance) or for specific internal workflows. This level of customization is difficult or impossible with API-only models.
- Brand Voice & Personality: Models can be trained to adhere to specific brand guidelines, tone, and style, ensuring consistent communication.
- Cost-Effectiveness and Resource Control:
- No API Fees: Companies can avoid the potentially high, recurring costs associated with proprietary API calls, especially for high-volume usage.
- On-Premises Deployment: The ability to run models on owned or private cloud infrastructure provides greater control over compute resources, costs, and data handling.
- Security, Privacy, and Data Governance:
- Data Sovereignty: For sensitive data or regulated industries, open-source models allow organizations to keep their data entirely within their own infrastructure, addressing critical privacy and security concerns.
- Auditability for Compliance: The transparency of open-source models facilitates easier auditing for compliance with regulations like GDPR or HIPAA.
- Democratization and Accessibility:
- Lower Barrier to Entry: Open-source models make advanced AI capabilities accessible to startups, small businesses, independent developers, and researchers who might lack the budget or resources to license proprietary models.
- Educational Tool: They serve as invaluable tools for learning about LLM architectures, training processes, and deployment strategies.
- Reduced Vendor Lock-in:
- Flexibility and Choice: Organizations are not tied to a single vendor's API, pricing structure, or product roadmap. They can switch between different open-source models or even blend them as needed.
- Performance Parity:
- Closing the Gap: Open-source models, especially those from Meta, Mistral, and Google, have rapidly closed the performance gap with their proprietary counterparts, often matching or exceeding them on many benchmarks, particularly after fine-tuning. This makes them viable, high-performance alternatives.
- Ethical Considerations and Transparency:
- Bias Mitigation: The open nature allows for community scrutiny and collaborative efforts to identify and mitigate biases inherent in training data or model behavior.
- Responsible AI: Transparency fosters responsible AI development by enabling better understanding of how models work and their potential societal impacts.
Tags: AI GPU Gemma Google Gemma LLM LLM Models Large Language Model Llama Llama 3 Mistral 7B Open-Source LLM  
|
 459
459  0
0  0
0 
 1982
1982 